The Privacy Moat: Engineering a Zero-Trust PII Redaction Pipeline
Introduction: Data as a Toxic Asset
In my previous posts, I discussed the philosophy of “Vibe Coding” and the infrastructure choices that power NanoLog. But as we move into 2026, the greatest engineering challenge isn’t performance—it’s safety. In a world where AI agents and autonomous systems are constantly planning and adaptively chaining actions across systems, the risk of data leakage is no longer theoretical; it is a systemic crisis.
At AHM Labs Ltd (the parent company of NanoLog), we view user data as a “toxic asset.” If you don’t need to hold it, don’t. If you must hold it, neutralize it. This mindset led us to build the NanoLog Redaction Engine, a multi-layered pipeline designed to scrub Personally Identifiable Information (PII) before it ever touches persistent storage.
Community Contribution: redact.nanolog.dev
Before we dive into the technical architecture, I’m excited to share that we’ve released a standalone version of our redaction technology. For researchers, legal teams, or anyone dealing with sensitive screenshots, you can use redact.nanolog.dev. It is a local-only tool; your images never leave your browser. It’s our contribution to a more private web.
The Architecture of “Toxic Data” Management
The NanoLog PII engine operates on a fundamental security guarantee: Raw, unredacted images never leave the server’s Node memory heap. We treat the raw buffer as a volatile substance. After processing, the buffers are actively zeroed out using buffer.fill(0) to prevent memory-dump exfiltration.
1. Text & Context Sanitization
Before a feedback record is even written to our database layer, we scrub the metadata.
- Context Stripping: We recursively remove keys like
userAgent,consoleErrors, and specificviewportdetails that could be used for fingerprinting. - Regex Scanning: We use deterministic scanning for standard PII—Emails, IP Addresses, and Phone Numbers—replacing them with
[EMAIL_REDACTED]tokens.
2. The Visual Redaction Pipeline (The 5-Pass Gauntlet)
The most complex part of our privacy moat is handling screenshots. When a user uploads a visual bug report, it goes through a 5-step classification engine to “burn in” black boxes over sensitive data, achieving more than 60% accuracy on standard screenshots.
| Pass | Type | Objective |
|---|---|---|
| Pass 1 | Regex Classifiers | Fast detection of SSNs, Credit Cards, API Credentials, and UK NI Numbers. |
| Pass 2 | Sliding Window | Catching PII split by OCR (e.g., “john @ example . com”). |
| Pass 3 | NLP (AI) | Natural Language Processing to help identify names and locations. |
| Pass 4 | Column Propagation | Auto-redacting entire tabular columns if >40% of the text is sensitive. |
| Pass 5 | Label Propagation | Redacting values directly adjacent to labels like “Account:” or “User:”. |
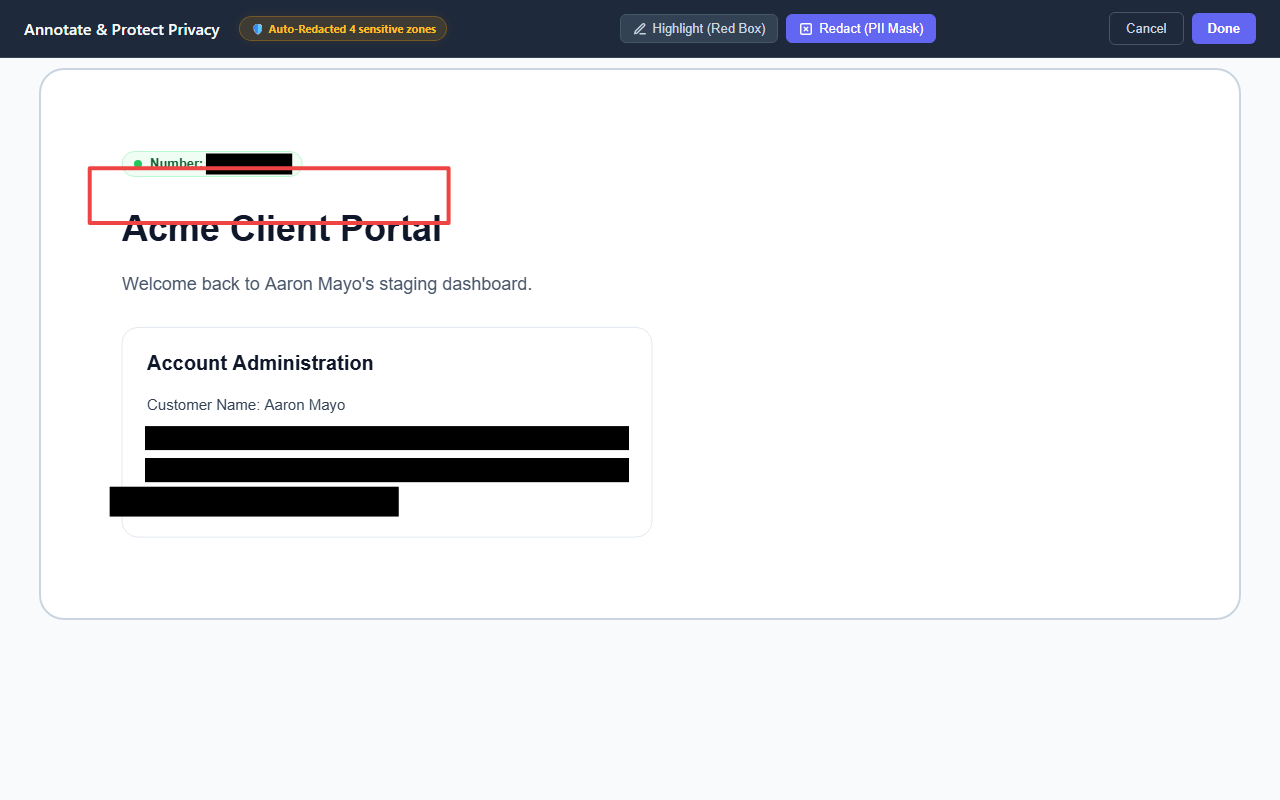
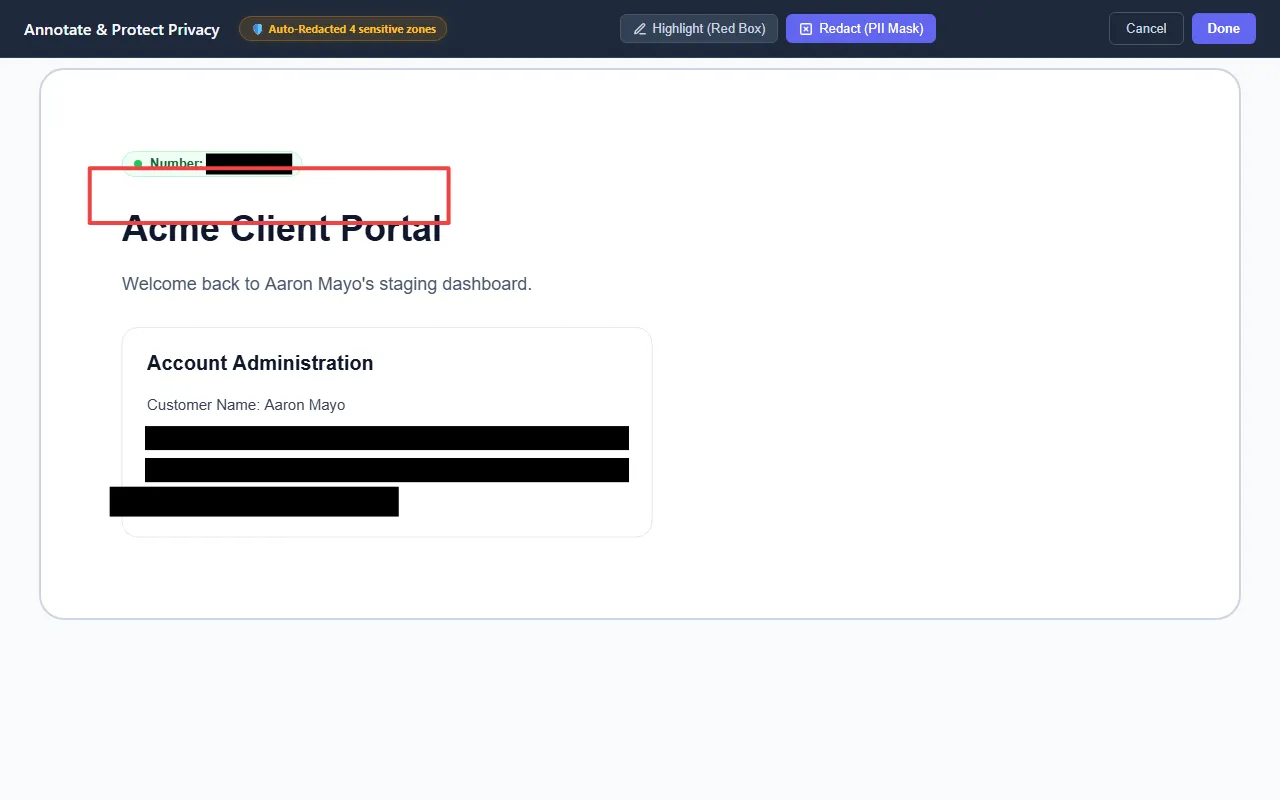 The client-side visual annotation editor, allowing users to manually redact or highlight areas of a bug report screenshot.
The client-side visual annotation editor, allowing users to manually redact or highlight areas of a bug report screenshot.
Deep Dive: AI-Powered Redaction with Natural Language Processing
Relying on regex isn’t enough in 2026. Names and locations are highly contextual. To solve this, AHM Labs is deeply invested in a wider privacy initiative utilizing Natural Language Processing (NLP).
We utilize a quantized BERT-base-NER model running locally on the CPU cache. This allows us to perform Named Entity Recognition (NER) to catch names (B-PER, I-PER) and locations (B-LOC) that escape traditional dictionaries. By running this via Xenova/transformers, we keep the pipeline blazing fast and—crucially—data localized. We don’t call external APIs for classification; the “brain” is inside our own security perimeter.
Spatial Intelligence: Layout-Aware Redaction
One of our unique innovations is Tabular and Horizontal Propagation. If the engine detects that a user is looking at a sensitive dashboard, it doesn’t just redact individual words.
- Tabular Awareness: If a vertical column in a screenshot is heavily redacted, the engine assumes the entire column is PII and blacks it out to preserve privacy even against OCR errors.
- Label Proximity: If the text “Password:” is found, the bounding box directly to its right is automatically marked for “burn-in,” even if the OCR couldn’t clearly read the password itself.
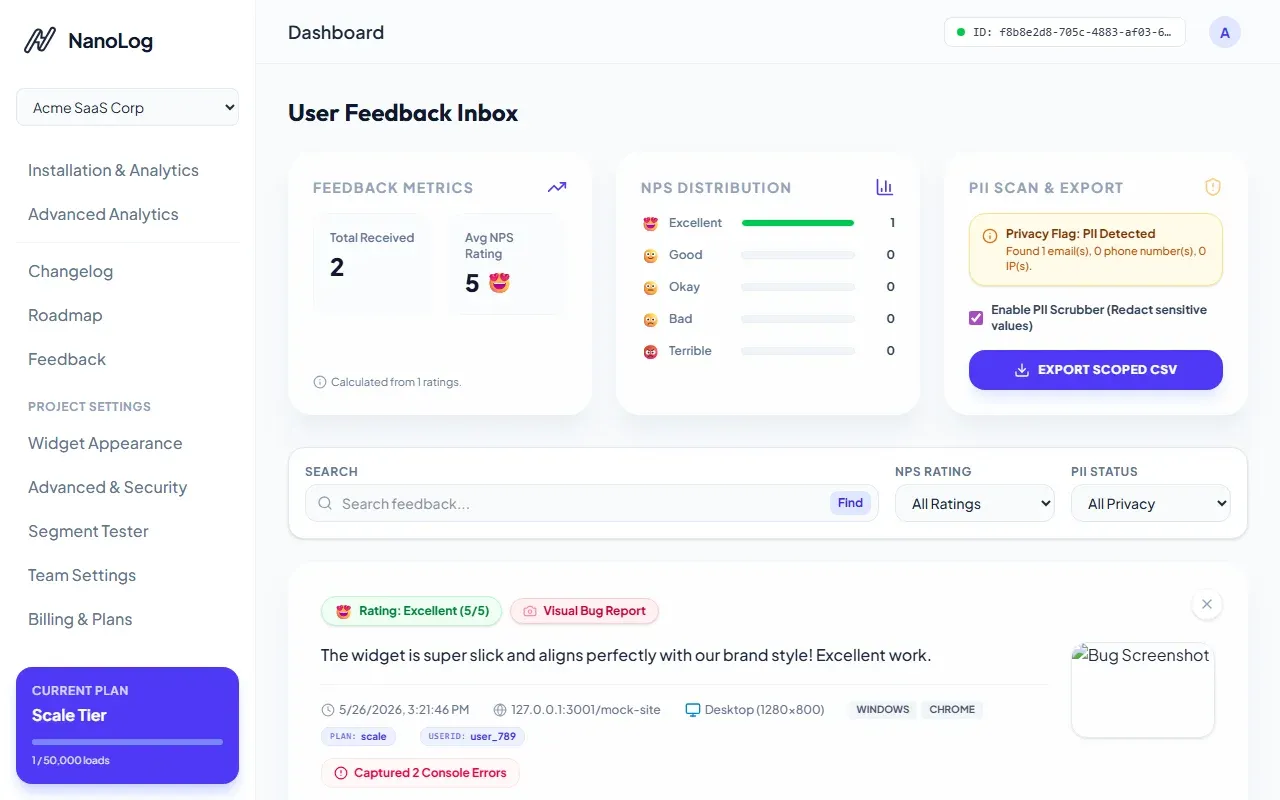 The NanoLog Feedback Inbox dashboard, showing customer feedback submissions with automated PII tags.
The NanoLog Feedback Inbox dashboard, showing customer feedback submissions with automated PII tags.
The Final Step: The “Sharp Burn”
Once all bounding boxes are collected, we generate an SVG overlay of solid black rectangles. We then use Sharp (high-performance C++ image processing) to composite this SVG onto the original WebP image. This is a permanent, destructive change—the pixels are gone, replaced by black blocks. The OCR layout data itself is then scrubbed so that the dashboard highlighting doesn’t accidentally reveal the redacted text.
Looking Ahead: AHM Labs and Enterprise Governance
This redaction pipeline is the first step in a larger mission. AHM Labs is currently developing a wider Enterprise AI Governance Hub. We are building toward a future where privacy isn’t a checkbox but a hard-coded architectural constant. Whether it’s managing the carbon footprint of AI inference or ensuring regional data sovereignty via carbon-aware routing, our goal is to make the agentic AI era as safe as it is productive.
See you in the next post, where we dive into the technical details of the Payment Choice and the Merchant of Record.
Authored by Aaron Harpermayo on June 8, 2026.